By inconspicuously attaching on clothing near a person’s mouth, the lavalier microphone (lav mic) provides multiple benefits when capturing dialogue. For video applications, there is no microphone distracting viewer attention, and the orator can move freely and naturally since they aren’t holding a microphone. Lav mics also benefit audio quality, since they are attached near the mouth they eliminate noise and reverberation from the recording environment.
Unfortunately, the freedom lav mics provide an orator to move around can also be a detriment to the audio engineer, as the mic can rub against clothing or bounce around creating disturbances often described as rustle. Here are some examples of lav-mic recordings where the person moved just a bit too much:
Rustle cannot be easily removed using the existing De-noise technology found in an audio repair program such as iZotope RX, because rustle changes over time in unpredictable ways based on how the person wearing the microphone moves their body. The material the clothing is made of also can have an impact on the rustle’s sonic quality, and if you have the choice attaching it to natural fibers such as cotton or wool is preferred to synthetics or silk in terms of rustling intensity. Attaching the lav mic with tape instead of using a clip can also change the amount and sound of rustle.
Because of all these variations, rustle presents itself sonically in many different ways from high frequency “crackling” sounds to low frequency “thuds” or bumps. Additionally, rustle often overlaps with speech and is not well localized in time like a click or in frequency like electrical hum. These difficulties made it nearly impossible to develop an effective deRustle algorithm using traditional signal processing approaches. Fortunately, with recent breakthroughs in source separation and deep learning removing lav rustle with minimal artifacts is now possible.
Audio Source Separation
Often referred to as “unmixing”, source separation algorithms attempt to recover the individual signals composing a mix, e.g., separating the vocals and acoustic guitar from your favorite folk track. While source separation has applications ranging from neuroscience to chemical analysis, its most popular application is in audio, where it drew inspiration from the cocktail party effect in the human brain, which is what allows you to hear a single voice in a crowded room, or focus on a single instrument in an ensemble.
We can view removing lav mic rustle from dialogue recordings as a source separation problem with two sources: rustle and dialogue. Audio source separation algorithms typically operate in the frequency domain, where we separate sources by assigning each frequency component to the source that generated it. This process of assigning frequency components to sources is called spectral masking, and the mask for each separated source is a number between zero and one at each frequency. When each frequency component can belong to only one source, we call this a binary mask since all masks contain only ones and zeros. Alternatively, a ratio mask represents the percentage of each source in each time-frequency bin. Ratio masks can give better results, but are more difficult to estimate.
For example, a ratio mask for a frame of speech in rustle noise will have values close to one near the fundamental frequency and its harmonics, but smaller values in low-frequencies not associated with harmonics and in high frequencies where rustle noise dominates.
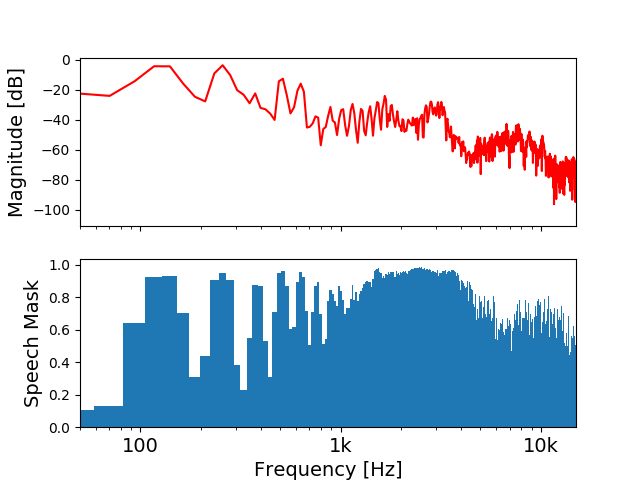
To recover the separated speech from the mask, we multiply the mask in each frame by the noisy magnitude spectrum, and then do an inverse Fourier transform to obtain the separated speech waveform.
Mask Estimation with Deep Learning
The real challenge in mask-based source separation is estimating the spectral mask. Because of the wide variety and unpredictable nature of lav mic rustle, we cannot use pre-defined rules (e.g., filter low frequencies) to estimate the spectral masks needed to separate rustle from dialogue. Fortunately, recent breakthroughs in deep learning have led to great improvements in our ability to estimate spectral masks from noisy audio (e.g., this interesting article related to hearing aids). In our case, we use deep learning to estimate a neural network that maps speech corrupted with with rustle noise (input) to separated speech and rustle (output).
Since we are working with audio we use recurrent neural networks, which are better at modeling sequences than feed-forward neural networks (the models typically used for processing images), and store a hidden state between time steps that can remember previous inputs when making predictions. We can think of our input sequence as a spectrogram, obtained by taking the Fourier transform of short-overlapping windows of audio, and we input them to our neural network one column at a time. We learn to estimate a spectral mask for separating dialogue from lav mic rustle by starting with a spectrogram containing only clean speech.
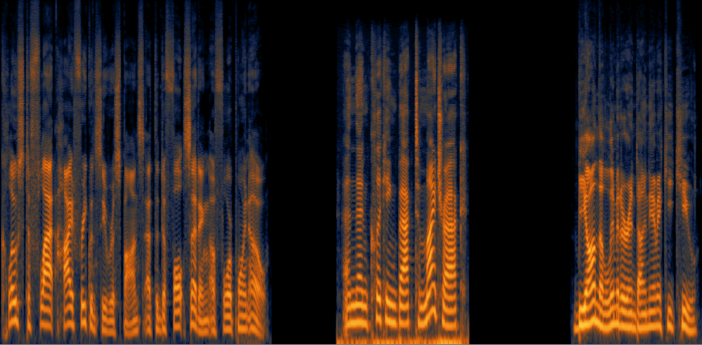
We can then mix in some isolated rustle noise, to create a nosiy spectrogram where the true separated sources are known.

We then feed this noisy spectrogram to the neural network which outputs a ratio mask. By multiplying the ratio mask with the noisy input spectrogram we have an estimate of our clean speech spectrogram. We can then compare this estimated clean speech spectrogram with the original clean speech, and obtain an error signal which can be backpropagated through the neural network to update the weights. We can then repeat this process over and over again with different clean speech and isolated rustle spectrograms. Once training is complete we can feed a noisy spectrogram to our network and obtain clean speech.
Gathering Training Data
We ultimately want to use our trained network to generalize across any rustle corrupted dialogue an audio engineer may capture when working with a lav mic. To achieve this we need to make sure our network sees as many different rustle/dialogue mixtures as possible. Obtaining lots of clean speech samples is relatively easy; there are lots of datasets developed for speech recognition in addition to audio recorded for podcasts, video tutorials, etc. However, obtaining isolated rustle noises is much more difficult. Engineers go to great lengths to minimize rustle and recordings of rustle typically are heavily overlapped with speech. As a proof of concept, we used recordings of clothing or card shuffling from sound effects libraries as a substitute for isolated rustle.
These gave us promising initial results for rustle removal, but only worked well for rustle where the mic rubbed heavily over clothing. To build a general deRustle algorithm, we were going to have to record our own collection of isolated rustle.
We started by calling into the post production industry to obtain as many rustle corrupted dialogue samples as possible. This gave us an idea of the different qualities of rustle we would need to emulate in our dataset. Our sound design team then worked with different clothing materials, lav mounting techniques (taping and clipping), and motions from regular speech gestures to jumping and stretching to collect our isolated rustle dataset. Additionally, in machine learning any patterns can potentially be picked up by the algorithm, so we also varied things like microphone type and recording environment to make sure our algorithm didn’t specialize to a specific microphone frequency response for example. Here’s a greatest hits collection of some of the isolated rustle we used to train our algorithm:
Debugging the Data
One challenge with machine learning is when things go wrong it’s often not clear what the root cause of the problem was. Your training algorithm can compile, converge, and appear to generalize well, but still behave strangely in the wild. For example, our first attempt at training a deRustle algorithm always output clean speech with almost no energy above 10 kHz, even though there was speech energy at those frequencies.
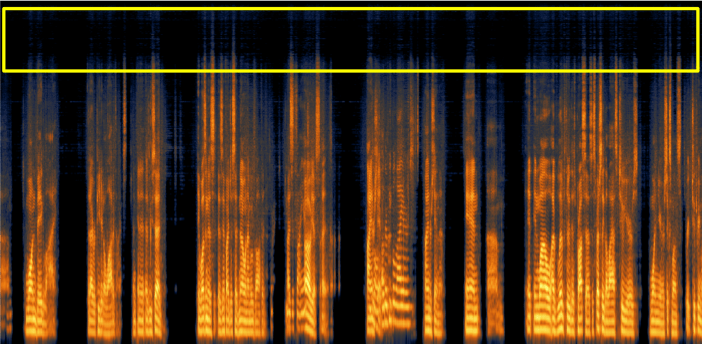
It turned out that a large percentage of our clean speech was recorded with a microphone that attenuated high frequencies. Here’s an example problematic clean speech spectrogram with almost no high-frequency energy:

Since all of our rustle recordings had high frequency energy the algorithm learned to assign no high frequency energy to speech. Adding more high quality clean speech to our training set corrected this problem.
Before and After Examples
Once we got the problems with our data straightened out and trained the network for a couple days on a NVIDIA K80 GPU, we were ready to try it out removing rustle from some pretty messy real-world examples:
Before
After
Before
After
Conclusion
While lav mics are an extremely valuable tool, if they move a bit too much the rustle they produce can drive you crazy. Fortunately, by leveraging advances in deep learning we were able to develop a tool to accurately remove this disturbance. If you’re interested in trying this deRustle algorithm give the RX 6 Advanced demo a try.

Could this process be improved by using a hybrid of machine learning and spectral repair noise sampling.
Ie, if you had a clean studio recording of an actors voice, could that be used to train the machine learning to exclude everything except that particular voice from noisy recordings of the same actor? Very interesting stuff indeed and I love the 2 new plugins.
LikeLiked by 1 person
Interesting idea to turn the ‘noise removal’ approach around. I can imagine that at some time in the future, such algorithms will be able to accurately identify a range of/all human voices and attenuate unwanted elements. I’m impressed with RX5 but 6 looks like a big leap forward. Nice work!
LikeLike
I believe this is part of how James Clarke at Abbey Road did the noise removal on the recent remix of Beatles Live at Hollywood Bowl. He mentioned, in an interview, getting samples of the various instruments in order to have a clear picture of the spectrum they occupied.
LikeLike
You could even imagine a system where an actor could collect or have collected a database of clean recordings of themselves and then could run those through the training algorithm to create a personalized preset that would more accurately recover their particular speech characteristics.
Going beyond that, this could be an adaptive process where, once the algorithm attains some predefined level of competency, the deRustled signal could potentially be fed back into the neural network to continue to adapt its models.
As a forensic tool, the uses are clear but maybe there’s also a use case where the algorithm could be tweaked by the user in some way in order to be used as more of an artistic effect and through the adaptive modeling learn that users preferences.
LikeLike